
Enjoy Threat Modeling? Try Threats in Models!
Previously…
In part 1 of this 4-part blog, we discussed Hugging Face, the potentially dangerous trust relationship between Hugging Face users and the ReadMe file, exploiting users who trust ReadMe and provided a glimpse into methods of attacking users via malicious models.
In part 2, we explore dangerous model protocols more in-depth– going into the technical reasons as to why exactly are models running code.
This is Part 2 of a four-part series: Part 1 ; Part 3 ; Part 4

Introduction to Model Serialization
A model is a program that was trained on vast datasets to either recognize or generate content based on statistical conclusions derived from those datasets.
To oversimplify, they’re just data results of statistics. However, do not be misled – models are code, not plain data. This is often stressed in everything ML, particularly in the context of security. Without going into too much detail – it is inherent for many models to require logic and functionality which is custom or specific, rather than just statistical data.
Historically (and unfortunately) that requirement for writable and transmittable logic encouraged ML developers to use complex object serialization as a means of model storage – in this case types of serialization which could pack code. The quickest solution to this problem is the notoriously dangerous pickle, used by PyTorch to store entire Torch objects, or its more contextual and less volatile cousin marshal, used by TensorFlow’s lambda layer to store lambda code.
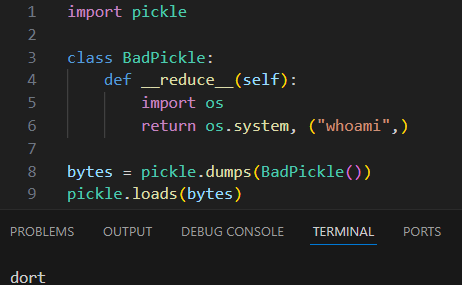
Please stop using this protocol for things. Please.
While simple serialization involves data (numbers, strings, bytes, structs), more complex serialization can contain objects, functions and even code – and that significantly raises the risk of something malicious lurking inside the models.

Writing’s on the wall there, guys
Protecting these dangerous deserializers while still using them is quite a task. For now, let’s focus on exploitation. This is quite well documented at this point, though there have been some curious downgrades exposed during this research.
Exploiting PyTorch
PyTorch is a popular machine learning library – extremely popular on Hugging Face andthe backbone of many ML frameworks supported on HF. We’ll have more on those (and how to exploit them) in a future blog.
PyTorch relies on pickling to save its output, which can contain an arbitrary method with arbitrary variables invoked upon deserialization with the load function; this works the same for PyTorch:
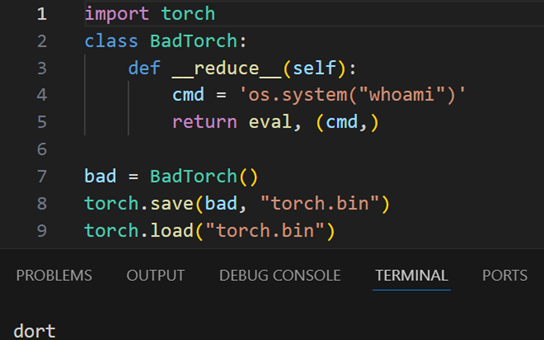
If this looks identical to the previous Pickle example to you then that’s because it is.
Note that the source code for BadTorch doesn’t need to be in scope – the value of __reduce__ is packed into the pickle, and its contents will execute on any pickle.load action.
To combat this, PyTorch added a weights_only flag. This flag detects anything outside of a very small allowlist as malicious and rejects it, severely limiting if not blocking exploitation. It is used internally by Hugging Face’s transformers, which explains why it can safely load torches even when dangerous and starting version 2.4 This flag is encouraged via a warning where it is stated that in the future this will be a default behavior.
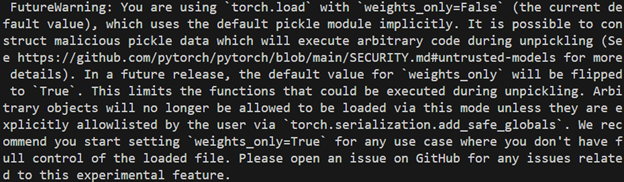
At the time of writing, PyTorch does not yet enable weights_only mode by default. Seeing how the rampant use of torch.load in various technologies is (this will be discussed in part 3), it would be safer to believe this change when we see it, because it is likely to be a breaking change. It would then be up to the maintainers whose code this change breaks to either adapt to this change or disable this security feature.
TensorFlow to Code Execution
TensorFlow, is a different machine learning library that offers various ways to serialize objects as well.
Of particular interest to us are serialized TensorFlow objects in protocols that may contain serialized lambda code. Since lambdas are code, they get executed after being unmarshled from Keras’, being a high-level interface library for TensorFlow.
Newer versions of TensorFlow do not generate files in the older Keras format (TF1, which uses several protobuf files or as h5).
To observe this, we can look at the older TensorFlow to 2.15.0, which allows generating a model that would be loaded using the malicious code (credit to Splinter0 for this particular exploit):
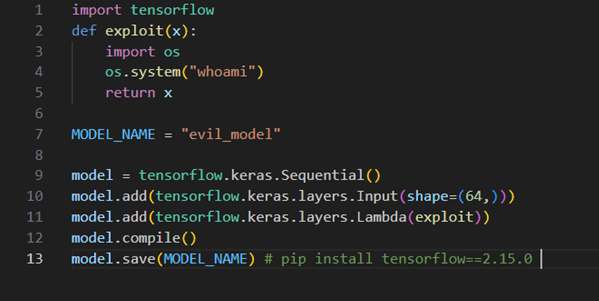
Note that the functionality to serialize lambdas has been removed in later versions of the protocol. For Keras, which supports Lambdas, these are now relying on annotations to link lambdas to your own code, removing arbitrary code from the process.
This could have been a great change if it eliminated support for the old dangerous formats, but it does not – it only removes serialization (which creates the payload) but not execution after deserialization (which consumes it).
Simply put – just see for yourself: if you generate a payload like the above model in an h5 format using the dangerous tensorflow 2.15.0, and then update your tensorflow:
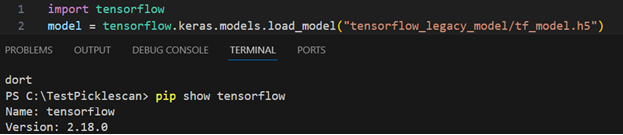
Exploit created on tensorflow 2.15.0, exploit pops like a champ on 2.18.0
In other words – this is still exploitable. It’s not really a Keras vulnerability (in the same vein torch.load “isn’t vulnerable”), though, but rather it’s a matter of how you end up using it – we’ve disclosed it amongst several other things to Hugging Face in August 2024, but more on that in a later write-up.
SafeTensors
Currently, Hugging Face is transferring models from a pickle format to SafeTensors, which use a more secure deserialization protocol that is not as naïve (but not as robust) as pickles.
SafeTensors simply use a completely different language (Rust) and a much simpler serialization protocol (Serde), which requires customization for any sort of automatic behavior post-deserialization.
Moving from Torch to SafeTensors
However, there is a fly in the SafeTensors ointment – importing. It makes sense that the only way to import from another format is to open it using legacy libraries, but it’s also another vulnerable way to invoke Torches. convert.py, a part of the SafeTensors library intended to convert torches to the SafeTensors format. However, the conversion itself is simply a wrapper for torch.load:
https://github.com/huggingface/safetensors/blob/main/bindings/python/convert.py#L186
The HF Devs are aware of this and have added a prompt – but that can be bypassed with a -y flag:
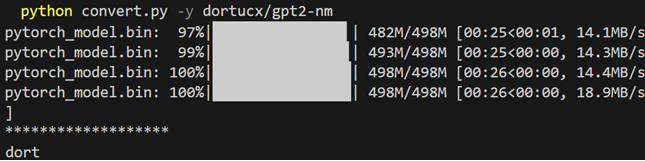
Model will run whoami on conversion. Disclaimer: image manipulated to exclude a bunch of passive warnings that might warn you, right after it’s way too late
The problem here is the very low trust barrier to cross – since, as discussed, most configuration is derived from ReadMe commands. This flag can simply be hidden between other values in instructions, which makes convert.py not just a conversion tool but also another vector to look out for.
There are many more conversion scripts in the transformers library that still contain dangerous calls to torch.load and can be found on the Transformers’ Github.
Conclusion
It’s interesting to see how what’s old is new again. Old serialization protocols which are easier to implement and use, are making a comeback through new, complex technology – particularly when security was never a concern during experimentation, and again becoming deeply ingrained in relatively new technology. The price for that speed is still being paid, with the entire ecosystem struggling to pivot to a secure and viable service by slugging through this tech debt.
There are several recommendations to be made when judging models by their format:
- With serialization mechanisms baked into the ecosystem, you should avoid the legacy ones, and review those that are middle-of-the-way and historically vulnerable.
- Consider a transition to SafeTensor or other protocols that are identified as secure and do not execute code or functions on deserialization and reject older potentially dangerous protocols.
- BUT never trust conversion tools to safely defuse suspicious models (without reviewing them first).
- And – as always – make sure you trust the maintainer of the Model.
On The Next Episode…
Now that we’ve discussed a couple of vulnerable protocols, we’ll demonstrate how they can be exploited in practice against Hugging Face integrated libraries. Read Part 3 now!
AI