
Introduction
GenAI has taken the world by storm. To meet the needs for development of LLM/GenAI technology through open-source, various vendors have risen to meet the need to spread this technology.
One well-known platform is Hugging Face – an open-source platform that hosts GenAI models. It is not unlike GitHub in many ways – it’s used for serving content (such as models, datasets and code), version control, issue tracking, discussions and more. It also allows running GenAI-driven apps in online sandboxes. It’s very comprehensive and at this point a mature platform chock full of GenAI content, from text to media.
In this series of blog posts, we will explore the various potential risks present in the Hugging Face ecosystem.

Championing logo design Don’ts (sorry not sorry opinions my own)
This is Part 1 of a four-part series: Part 2 ; Part 3 ; Part 4
Hugging Face Toolbox and Its Risks
Beyond hosting models and associated code, Hugging Face is a also maintainer of multiple libraries for interfacing with all this goodness – libraries for uploading, downloading and executing models to the Hugging Face platform. From a security standpoint – this offers a HUGE attack surface to spread malicious content through. On that vast attack surface a lot has already been said and many things have been tested in the Hugging Face ecosystem, but many legacy vulnerabilities persist, and bad security practices still reign supreme in code and documentation; these can bring an organization to its knees (while being practiced by major vendors!) and known issues are shrugged off because “that’s just the way it is” – while new solutions suffer from their own set of problems..
ReadMe.md? More Like “TrustMe.md”
The crux of all potentially dangerous behavior around marketplaces and repositories is trust – trusting the content’s host, trusting the content’s maintainer and trusting that no one is going to pwn either. This is also why environments that allow obscuring malicious code or ways to execute it are often more precarious for defenders.
While downloading things from Hugging Face is trivial, actually using them is finnicky – in that there is no one global definitive way to do so and trying to do it any other way than the one recommended by the vendor will likely end in failure. Figuring out how to use a model always boils down to RTFM – the ReadMe.
But can ReadMe files be trusted? Like all code, there are good and bad practices – even major vendors fall for that. For example, Apple actively uses dangerous flags when instructing users on loading their models:

trust_remote_code sounds like a very reasonable flag to set to True
There are many ways to dangerously introduce code into the process, simply because users are bound to trust what the ReadMe presents to them. They can load malicious code, load malicious models in a manner that is both dangerous and very obscure.
Configuration-Based Code Execution Vectors
Let’s start by examining the above configurations in its natural habitat.
Transformers is one of the many tools Hugging Face provides users with, and its purpose is to normalize the process of loading models, tokenizers and more with the likes of AutoModel and AutoTokenizer. It wraps around many of the aforementioned technologies and mostly does a good job only utilizing secure calls and flags.
However – all of that security goes out the window once code execution for custom models that load as Python code behind a flag, “trust_remote_code=True”, which allows loading classes for models and tokenizers which require additional code and a custom implementation to run.
While it sounds like a terrible practice that should be rarely used, this flag is commonly set to True. Apple was already mentioned, so here’s a Microsoft example:
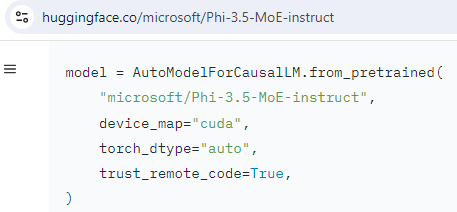
why wouldn’t you trust remote code from Microsoft? What are they going to do, force install Window 11 on y- uh oh it’s installing Windows 11
Using these configurations with an unsecure model could lead to unfortunate results.
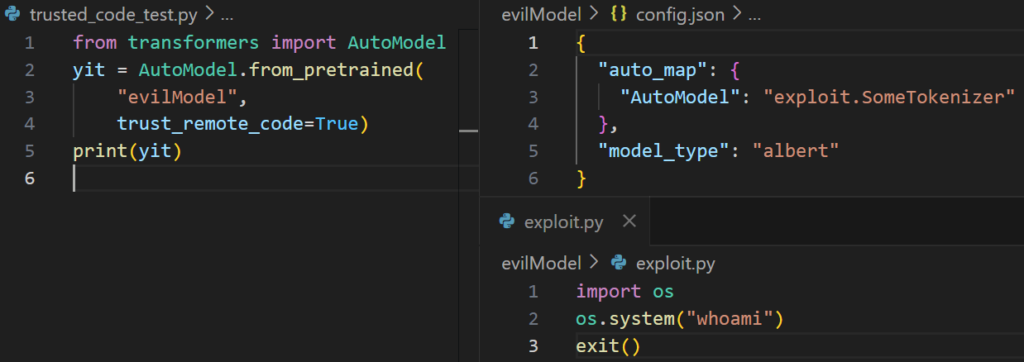
Code loads dangerous config à config loads code module à code loads OS command
- Code will attempt to load an AutoModel from a config with the trust_remote_code flag
- Config will then attempt to load a custom class model from “exploit.SomeTokenizer” which will import “exploit” first, and then look for “SomeTokenizer” in that module
- SomeTokenizer class doesn’t exist but exploit.py has already been loaded, and executing malicious commands
This works for auto-models and auto-tokenizers, and in transformer pipelines:

in this case the model is valid, but the tokenizer is evil. Even easier to hide behind!
Essentially this paves the way to malicious configurations – ones that seem secure but aren’t. There are plenty of ways to hide a True flag looking like a False flag in plain sight:
- False is False
- {False} is True – it’s a dict
- “False” is True – it’s a str
- False < 1 – is True, just squeeze it to the side:

This flag is set as trust_remote_code=False……………………………………………………………………………….………….n’t
While these are general parlor tricks to hide True statements that are absolutely not exclusive to any of the code we’ve discussed – hiding a dangerous flag in plain sight is still rather simple. However, the terrible practice by major vendors to have this flag be popular and expected means such trickery might not even be required – it can just be set to True.
Of course, this entire thing can be hosted on Hugging Face – models are uploaded to repos in profiles. Providing the name of the profile and repo will automatically download and unpack the model, only to load arbitrary code.
import transformers
yit = transformers.AutoTokenizer.from_pretrained(“dortucx/unkindtokenizer”, trust_remote_code=True)
print(yit)
Go on, try it. You know you want to. What’s the worst that can happen? Probably nothing. Right? Nothing whatsoever.
Dangerous Coding Practices in ReadMes
Copy-pasting from ReadMes isn’t just dangerous because they contain configurations in their code, though – ReadMes contain actual code snippets (or whole scripts) to download and run models.
We will discuss many examples of malicious model loading code in subsequent write-ups but to illustrate the point let’s examine the huggingface_hub library, a Hugging Face client. The hub has various methods for loading models automatically from the online hub, such as “huggingface_hub.from_pretrained_keras”. Google uses it in some of its models:

And if it’s good enough for Google, it’s good enough for everybody!
But this exact method also supports dangerous legacy protocols that can execute arbitrary code. For example, here’s a model that is loaded using the exact same method using the huggingface_hub client and running a whoami command:

A TensorFlow model executing a “whoami” command, as one expects!
Conclusions
The Hugging Face ecosystem, like all marketplaces and open-source providers, suffers from issues of trust, and like many of its peers – has a variety of blindspots, weaknesses and practices the empower attackers to easily obscure malicious activity.
There are plenty of things to be aware of – for example if you see the trust_remote_code flag being set to True – tread carefully. Validate the code referenced by the auto configuration.
Another always-true recommendation is to simply avoid untrusted vendors and models. A model configured incorrectly from a trusted model is only trustworthy until that vendor’s account is compromised, but any model from any untrusted vendor is always highly suspect.
As a broader but more thorough methodology, however, a user who wants to securely rely on Hugging Face as a provider should be aware of many things – hidden evals, unsafe model loading frameworks, hidden importers, fishy configuration and many, many more. It’s why one should read the rest of these write-ups on the matter.
On The Next Episode…
Now that we’ve discussed the very basics of setting up a model – we’ve got exploit deep-dives, we’ve got scanner bypasses, and we’ve also got more exploits. Read Part 2 now!
AI