
It starts with a CVE
There is no doubt that NVD (National Vulnerability Database) is the go-to reference when it comes to the universe of vulnerabilities. For one thing, it is the most comprehensive database. By the time of writing this, it contains more than 185 thousand vulnerabilities. Since NVD is the best solution to keep track of security issues, we at Checkmarx adopted CVE (Common Vulnerabilities and Exposures) as the main identifier for our vulnerabilities.
Apart from just tracking and numbering vulnerabilities, NVD is a solid ground of information—it collects additional useful data for interested parties. For us, NVD is a starting point for much deeper research.
Let’s draw the curtains
So, every day, the Checkmarx SCA (Software Composition Analysis) Team receives all the new vulnerabilities (CVEs) that come from the NVD.
From those, we filter what’s relevant for us:
- Since SCA operates in the open-source market, we put aside all the CVEs that are not related to open source packages.
- Then we only get the CVEs for the languages and package managers that our clients need—the ones we offer support for.
And since at Checkmarx we value quality, we don’t just limit ourselves to getting data from the NVD.
In Checkmarx SCA, that’s where the core of our work comes in. The analysts got the petroleum, and now they need to turn it into fuel. Hence, each CVE must undergo a meticulous research process before that data is ready to be used in our SCA.
Information, more information
Let’s take CVE-2018-16469 as an example.
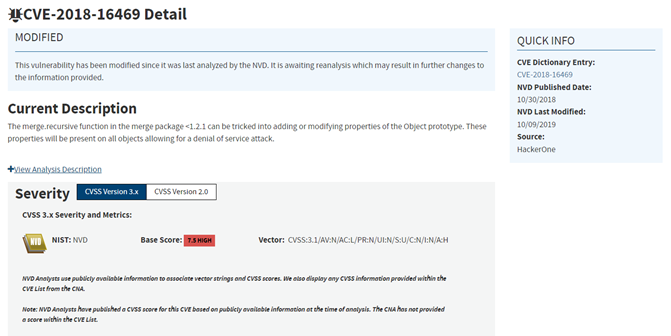
NVD’s information is our first chance to begin building some initial understanding.
- What is the vulnerability? Prototype Pollution that might lead to a Denial of Service attack?
- Which product is affected? NPM package “merge”?
- How severe is it? It can have a High Impact in the Availability (CVSS score of 7.5)?
- Etc.
Then we get hands-on with as much information as possible—information is our friend. We start by looking for leads, checking external references, the repository, related issues, official disclosures (like https://hackerone.com/reports/381194), etc.
At this point, the data we’ve gotten so far is fairly trustworthy, but now we need to:
- Start validating everything and developing a more solid understanding.
- If we confirm that NVD’s data (Description, CWE, CVSS, etc.) is correct and suitable, that’s what we will want to show our customers. If possible, it’s good to be aligned with the number-one reference.
- However, if something is not correct, we will investigate further and fix the information accordingly. If we know of a more appropriate CWE, we will change it. For instance, here we replaced the Weakness Enumeration CWE-20 with CWE-1321, which back then was still in neglect, but it’s more proper for Prototype Pollution.
Show me where
We work with packages for package managers, but NVD often mentions the product and not a specific package. So, it’s fundamental that we discover which packages are affected. Here, it’s the NPM package “merge”.
Sometimes packages are affected by using vulnerable code from another package, like wrappers. We know that often the vulnerability is in the actual product, but finding the exact vulnerable source is not straightforward. For example, usually in Maven, the “core” packages (which contain most of the source code) are vulnerable. But we don’t want to limit to the “core” since it’s more general. Instead, we aspire to identify the specific artifact that contains the vulnerable code.
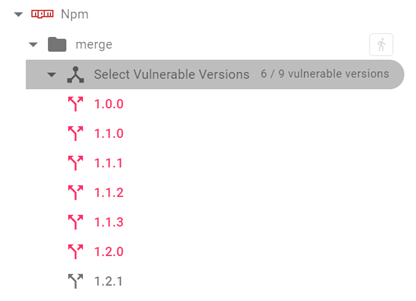
Another focal point here is the versions of the product. NVD’s description mentions the affected versions, but often not all versions are mentioned, or sometimes the mentioned versions are not correct—like this one that described versions prior to 6.4.9 as affected. But we found version 6.4.9 was vulnerable as well. For this, we lean on different methodologies and tools. Release Notes can be valuable, Commits are an immense help. But also, Disclosures, Issues, Pull Requests, etc. are valuable as well. Above all, we aim to confirm the exact fixed and vulnerable versions, which, among other methods, can be achieved by comparing the code between different versions or checking the source code.
Back to the initial example, we can confirm that the fix was released in version 1.2.1, with the line ` if (key === ‘__proto__’) continue; `.
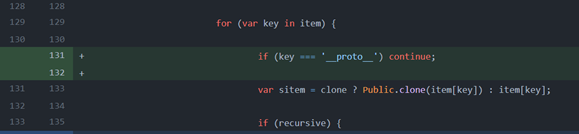
We then mark each version accordingly and fix the description if needed so that Checkmarx SCA scan will respond precisely to the customer’s products.
Those references that we find along the way might have valuable information to show our customers, especially those curious to know and read more. In that sense, we also supply the links for all the relevant references.
Yet, we need to make our results even more fulfilling. We don’t just want to show where the vulnerability exists through references. That’s why we have the Exploitable Path feature. Our analysts work exhaustively to make sure that they don’t miss any possible location for the vulnerability. We try hard to identify the vulnerable files, classes, and functions where the vulnerability lies.
A few last words
We went through a deep research process to make the CVE data as accurate as possible, but before it becomes available in Checkmarx SCA, we must make sure that the end product is correct. In that sense, each CVE moves in line to be reviewed by our experienced team. If everything aligns with our internal practices, then the CVE can be approved and will finally be ready to enter our SCA scans.
By going through this process, and meticulously following these steps for each CVE, we guarantee that data that shows in our SCA gets curated in the best interests of quality. It’s also why our number of False Positives or Negatives is so low.
…
Checkmarx SCA not only excels in identifying vulnerabilities in packages that you directly scan but also in all the vulnerable dependencies that you might have in your code. If you use open-source packages (which you likely do), your code might be exposed and insecure. If you have never tried Checkmarx SCA before, request your demo here. We will be glad to help.
AppSec
Article
Awareness
English
Open-Source Security
SCA
SSCS