With advanced AI models capable of generating working exploits in minutes for under a dollar, no vulnerability is too small to ignore. The security calculus has fundamentally changed, and the only winning strategy runs on two tracks simultaneously: remediate everything in the backlog and stop new vulnerabilities from entering the codebase at all.
The Old Playbook No Longer Works
For years, security teams operated on a pragmatic assumption: not every vulnerability is equal. Prioritize critical and high-severity findings. Let medium and low age in the backlog. There was logic to this approach — resources are finite, and triaging CVSS score felt like rational risk management.
That logic is now obsolete.
The arrival of advanced large language models has detonated the foundation beneath severity-based triage. These models do not read CVE databases the way humans do — they reason through code, identify attack vectors, and generate working exploits autonomously. The result is a threat environment where the old categories of “critical” versus “low” risk are becoming meaningless distinctions.
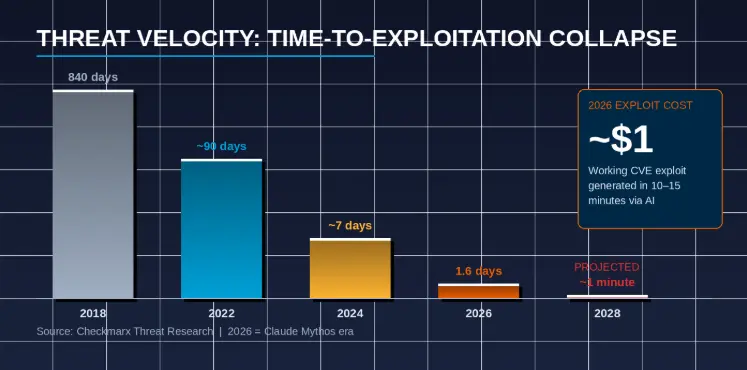
Consider the trajectory: in 2018, it took an attacker an average of 840 days to exploit a disclosed vulnerability. By 2026, that number has collapsed to 1.6 days. Security researchers project it will reach one minute by 2028. Meanwhile, the cost of generating a working exploit has dropped to approximately $1, achievable in 10 to 15 minutes using commodity AI tools.
The most alarming proof point arrived in April 2026 with Claude Mythos, Anthropic’s most capable model. In independent testing, Mythos achieved a 72.4% exploit success rate against known vulnerabilities — compared to 14.4% for Opus 4.6 and 4.4% for Sonnet 4.6. For context, the model designed for reasoning and safety is now among the most capable offensive security tools ever tested.
The implication is stark: a vulnerability your team rated “low severity” and deprioritized two years ago can now be weaponized by an adversary using an AI model, in minutes, for less than the cost of a cup of coffee. The backlog is not a sorted list of future work. It is a list of open attack surfaces — every item on it, regardless of its original severity score.
The industry is already feeling this in practice. Bug bounty programs – long structured around 30-to-60-day disclosure and remediation cycles, are collapsing under the weight of AI-speed weaponization. What once gave organizations a reasonable window to assess, triage, and patch is now measured in hours, not weeks. Security leaders who have spoken to Checkmarx’s have been consistent in their reaction: this is happening, and it is happening at a scale larger than anyone anticipated.
The pressure extends to release cycles themselves. As new AI models emerge with increasingly sophisticated reasoning capabilities, they surface new attack vectors against existing code, meaning a vulnerability that was practically unexploitable last quarter may become a live risk the moment the next frontier model ships. Release cadences will need to become far more dynamic, with security gates that respond to the threat environment in real time rather than on a fixed calendar.
Front One: Get the Backlog to Zero
The first strategic imperative is a mindset shift: the remediation backlog is not a queue to be managed. It is a liability to be eliminated. Every unresolved vulnerability, regardless of its original severity rating, represents a door that a capable AI adversary can now open.
Why Severity Scoring Has Lost Its Primacy
Traditional CVSS scoring was designed for a world where exploiting a vulnerability required genuine expertise, time, and effort. A “low” score reflected the realistic difficulty of weaponization. That friction no longer exists.
Advanced LLMs can reason through code the way a skilled human security researcher would — but at machine speed, at near-zero cost, and without fatigue. A vulnerability that was previously difficult to exploit because it required understanding complex application logic, chaining multiple conditions, or crafting a precise payload is now within reach of any adversary with API access to a frontier model.
This does not mean severity scores are worthless for ordering work. It means they can no longer be used to justify inaction. A “low” vulnerability left unresolved is not a calculated risk — it is an invitation.
The Agentic Remediation Imperative
Getting to zero is not achievable through human effort alone. The math does not work. Security teams are already buried: 81% of companies knowingly ship vulnerable code because backlogs are growing faster than teams can manually remediate. AI-generated code compounds this further — every AI coding session produces approximately 1.7x more issues than human-written code, and roughly 45% of AI model solutions are insecure.
The response must be agentic. Security teams need AI-powered remediation pipelines that do not just surface findings but close them — automatically, at the pull request level, prioritized by what is actually exploitable in the production environment. The goal is not faster triage. The goal is autonomous closure at scale.
This is where attackability-based prioritization becomes essential. Not all of those 22,500 raw findings across a typical enterprise codebase represent equal danger. The critical filter is not severity — it is reachability and exploitability in the specific production context. A confirmed exploitable vulnerability in a code path that handles authentication for a production system is categorically different from a theoretical flaw in a dead code branch. Checkmarx’s fidelity funnel reduces that 22,500 raw findings to 500 actionable risks — then agentic remediation closes 7 out of 9 confirmed findings automatically.
The proof point: mean time to remediation drops from six hours to 1.8 minutes. That is not an incremental improvement. That is a different operational model entirely.
Remediation at Zero: What It Requires
Getting the backlog to zero at enterprise scale requires three capabilities working in concert:
- Attackability scoring: Confirming reachability and exploitability in the production environment, not just in the abstract. This is the step that separates signal from noise at scale.
- Agentic fix generation: AI-generated patches applied at the PR level, validated before merge, and executed without developer interruption for the majority of findings.
- Continuous scheduled coverage: AppSec must operate as a continuous practice, not a quarterly audit. Scheduled scan cadences normalize remediation as an ongoing operational rhythm — not a reactive fire drill.
Front Two: Prevent at the Point of Creation
Eliminating the existing backlog is necessary. It is not sufficient. If the prevention layer does not move left — all the way to the moment code is generated with AI — remediation teams will be permanently fighting upstream production.
The economics of AI-generated code have created a structural problem: LLMs give developers unprecedented velocity, but they simultaneously introduce vulnerabilities at scale. Approximately one in three lines of code written today is AI-generated. Nearly half of AI model solutions contain security flaws. Old vulnerability classes that legacy SAST tools were trained to catch are being reintroduced at speed — not by inexperienced developers, but by models that do not natively reason about application security context.
The response is not to slow AI adoption. It is to make security native to the AI development workflow.
Security at the Prompt Level
The earliest possible intervention is at the prompt — before insecure code is even generated. When a developer interacts with an AI coding assistant inside an IDE like Cursor, Windsurf, VS Code, AWS Kiro, or Claude Code, that is the moment to apply security guardrails. Real-time scanning engines running alongside the AI assistant can catch insecure patterns as they emerge, before they are committed, before they enter a PR, before they compound the backlog.
This is not a suggestion to make developers slow down. Early-stage interception is faster and cheaper than downstream remediation. Fixing a vulnerability at the IDE takes seconds. Fixing it after it reaches production — or after it is exploited — takes days, or worse. Checkmarx Developer Assist users report a 50% boost in productivity precisely because security feedback arrives in context, in real time, without breaking flow.
Security Inside the AI Pipeline
Prevention cannot stop at the developer’s keyboard. Modern software is built not just by humans using AI, but by AI agents executing autonomous coding workflows — writing code, making commits, opening PRs, and triggering deployments with minimal human review in the loop.
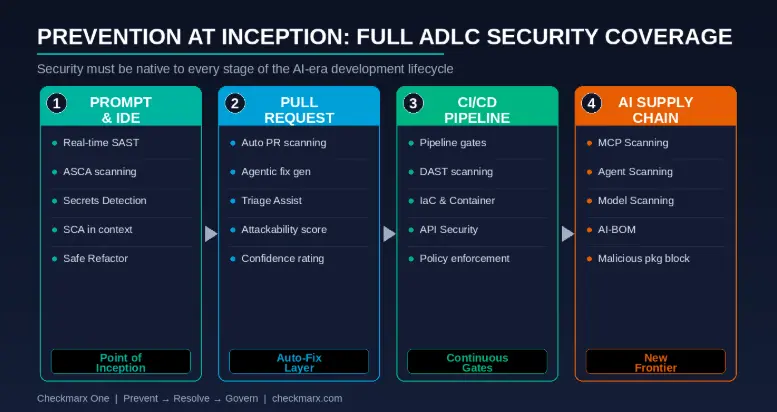
Every stage of this pipeline is a potential insertion point for security vulnerabilities: the IDE, the pull request, the CI/CD pipeline, and the AI supply chain itself. Security coverage must span the entire application development lifecycle (ADLC), not just the code repository.
This means securing:
- The IDE layer: real-time SAST, SCA, secrets detection, and IaC scanning as code is written.
- The PR layer: automated scanning and agentic fix generation triggered on every pull request before merge.
- The pipeline layer: continuous scanning integrated into CI/CD, enforcing security gates without slowing release velocity.
- The AI supply chain: scanning MCP servers, AI agents, and AI models for embedded risks, malicious packages, and supply chain tampering — a category of risk that has no coverage in any LLM-native AppSec tool today.
The AI Supply Chain Risk No One Is Talking About
There is a third dimension of AI-era risk that most security programs have not yet addressed: the AI supply chain. When development teams adopt AI coding assistants, MCP (Model Context Protocol) servers, and autonomous AI agents as part of their workflow, they introduce new vectors for supply chain compromise that traditional AppSec tools were never designed to detect.
A malicious MCP server can exfiltrate credentials or inject malicious code into an agent’s output. An AI model with embedded bias or a compromised training provenance can systematically introduce vulnerabilities, representing a scale of attacks that no human review process can match.
Prevention at the point of inception means covering this layer too: an AI Bill of Materials (AI-BOM) that provides deterministic discovery of every AI component in the development workflow, mapped to compliance frameworks including NIST AI RMF, the EU AI Act, ISO 42001, and OWASP LLM Top 10.
Why General-Purpose LLMs Cannot Solve This Problem
There is a seductive narrative circulating in the market: the same AI models creating the security problem can also solve it. This is not supported by the evidence.
In independent benchmarking, the best general-purpose LLMs detect approximately 25 to 28% of known vulnerabilities in real codebases. That means 72 to 75% of vulnerabilities remain undetected — while false positive rates run between 36 and 52%, generating exactly the kind of analyst noise that buries security teams. Claude Opus 4.6, even with strong prompting and tool access, detects only 28.5% of vulnerabilities. An AI cannot effectively self-police the code it generates.
The structural limitations are not model-specific. LLMs lack taint tracking and data flow analysis required for true SAST. They cannot confirm reachability — Anthropic’s own documentation explicitly states that reviewing code “cannot confirm whether that code is reachable in production.” They cannot perform runtime testing (DAST). They produce non-deterministic outputs that fail enterprise audit requirements. And they have no native capability for AI Supply Chain coverage.
The asymmetry is alarming: LLM offense improved approximately 100x between 2024 and 2026 (from near-zero autonomous exploit capability to 72.4% with Mythos), while LLM defense improved only 2x (from 12.9% to 28.5% detection rate). General-purpose models are not closing this gap. They are widening it.
Purpose-built AppSec infrastructure — combining deterministic scanning engines, AI-augmented triage, attackability confirmation, DAST, and agentic remediation — is the only architecture designed to operate at the speed and scale this threat environment demands.
The Two-Front Mandate
Security leaders face a simultaneous mandate that cannot be sequenced. You cannot clear the backlog first and then shift left. By the time the backlog is cleared, the prevention gap will have refilled it. Both fronts must advance in parallel.
Front One: Remediation-led, backlog-to-zero
Treat every item in the vulnerability backlog as an active risk, regardless of its original severity rating. Deploy attackability scoring to confirm exploitability in the production context. Apply agentic remediation to close findings automatically at scale. Establish continuous scheduled scanning to normalize AppSec as an operational practice, not a point-in-time audit.
Front Two: Prevention at inception
Bring security into the AI coding workflow — at the prompt, in the IDE, inside the CI/CD pipeline, and across the AI supply chain. Security must be native to the development experience, not a gate at the end of it. When developers receive real-time, high-confidence security feedback in context, they fix issues immediately rather than generating backlog for the next cycle.
Organizations that execute on both fronts simultaneously will emerge from the AI era with security programs that can match the pace of innovation. Those that treat remediation and prevention as sequential will find themselves perpetually behind a threat environment that operates at machine speed.
Where Innovation and Security Move as One
The AI era has not made application security harder. It has made the consequences of failing at it more immediate, more costly, and more visible. Adversaries now have access to the same generative AI capabilities that are powering the development productivity boom — and they are using those capabilities to compress the window between vulnerability disclosure and active exploitation to near zero.
The organizations that will thrive are those that refuse to treat security as a trade-off against velocity. The Prevent → Resolve → Govern model — catching vulnerabilities at inception, resolving them agentically at scale, and governing continuous coverage as an operational discipline — is the architecture of that future.
Two fronts. One risk. No vulnerabilities left behind.
The architecture that closes both fronts is the same: a security control plane that sits outside the AI systems it governs. Checkmarx’s whitepaper on LLM Application Security breaks down exactly how — from the four critical ADLC control points to the hybrid deterministic-plus-AI framework built for the speed this threat environment demands.
Read it here.
ADLC
AI generated code
AppSec
LLM
Mythos